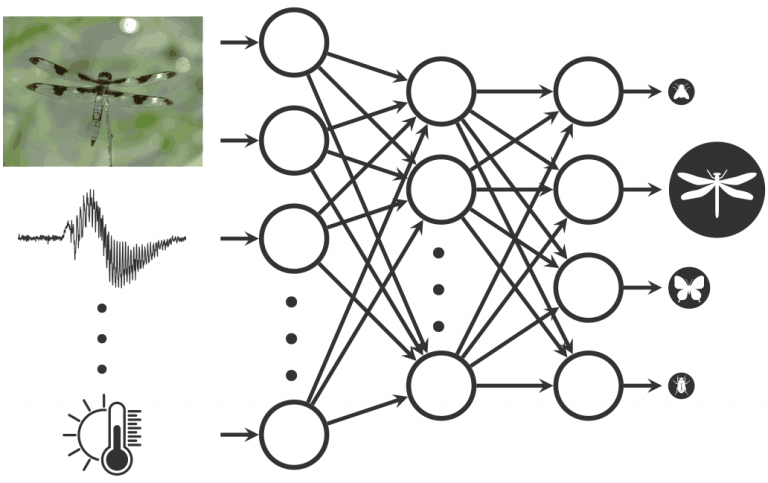
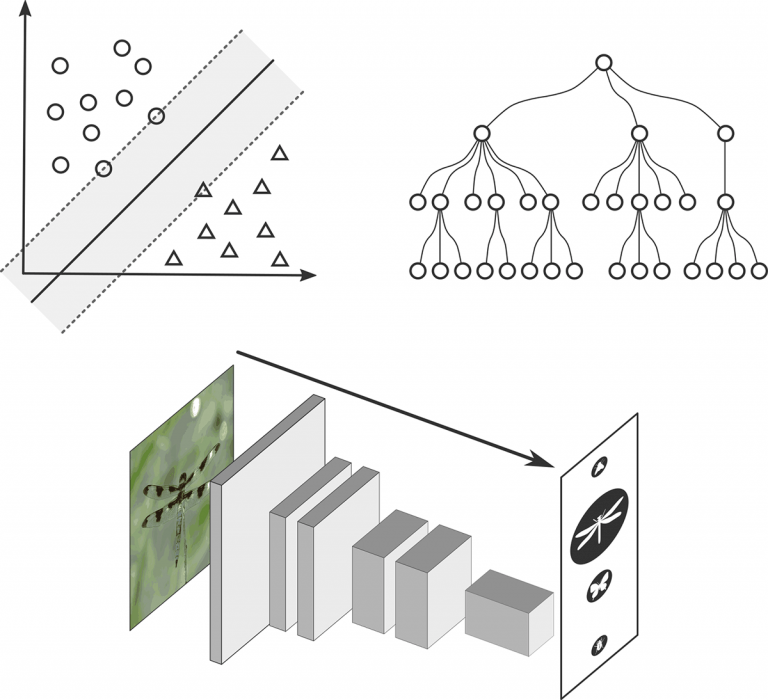
Seit einigen Jahren gibt es eine ganze Reihe von etablierten KI-Modellen für die Bilderkennung. Prominente Beispiele sind tiefe NN für die Unterscheidung von über tausend häufigen Objektkategorien, z.B. Goldfisch, Banane, Orange,… . Eine Artbestimmung von Insekten auf Bildern bietet allerdings besondere Herausforderungen: Die Unterschiede (Varianz) zwischen Bildern von Insekten derselben Art sind oft größer als die zwischen Bildern unterschiedlicher Arten (kleine Interspezies-Varianz und große Intraspezies-Varianz, Fine Grained Visual Categoriziation (FGVC)-Problem). Darüber hinaus werden wir in den Trainingsdaten von selten vorkommenden Arten nur sehr wenige Datensätze haben (Long Tail Distribution). Andererseits haben wir nicht nur Bilddaten zur Verfügung, sondern multimodale Daten, die wir geeignet zusammenfügen müssen in einem KI-Modell. Daher müssen wir problemangepasste KI-Modelle entwerfen.
Gerade arbeiten wir z.B. daran, eine sogenannte hierarchische Klassifikation durchführen, bei der ein Insekt im taxonomischen Baum nicht unbedingt bis zur Art bestimmt wird, sondern nur bis zur Gattung oder Ordnung. Es gibt viele offene Fragen: Ist es sinnvoll, Unternetzwerke für charakteristische Regionen wie Flügel, Hinterleib oder Kopf zu verwenden? Wie gehen wir mit den stark unbalancierten Trainingsdaten um (Data Augmentation, Few Shot Learning)? Wie berücksichtigen wir Metadaten wie z.B. Temperatur, Tages- oder Jahreszeit zusammen mit Vorwissen über das Verhalten und Vorkommen einzelner Insektenarten?